
Google’daki yapay zeka araştırmacıları, bir yıl önce önemli bir yeni program olan Pathways Language Model’i (PaLM) ortaya çıkardığında, bu programda birkaç yüz kelime harcadılar. teknik bir belge programın sonuçlarını elde etmek için kullanılan yeni yapay zeka tekniklerinin açıklamasına.
Geçen hafta PaLM halefi olan PaLM 2’nin sunumu sırasında Google neredeyse hiçbir şey açıklamadı. sonunda bir eke eklenen tek bir tabloda 92 sayfalık teknik raporGoogle araştırmacıları, bu sefer hiçbir şey söylemeyeceklerini çok kısaca anlatıyor:
PaLM-2, son teknolojiye sahip yeni bir dil modelidir. Model boyutuna bağlı olarak değişken ayarlarla, Transformer mimarisine dayalı yığılmış katmanları kullanan küçük, orta ve büyük değişkenlerimiz var. Modelin boyutu ve mimarisi hakkında daha fazla ayrıntı şirket dışında açıklanmadı..
AI yayıncılığının tüm tarihinde bir dönüm noktası
PaLM 2’nin mimarisi olarak adlandırılan şeyin, yani programın oluşturulma biçiminin ifşa edilmesinin kasıtlı olarak reddedilmesi, yalnızca PaLM ile ilgili önceki makaleyle çelişmekle kalmaz, aynı zamanda AI yayıncılığının tüm tarihinde bir dönüm noktası oluşturur. çoğunlukla özgür yazılım koduna dayalıdır ve her zaman programın mimarisi hakkında önemli ayrıntılar içerir.
Bu, açıkça, Google’ın en son “üretken AI” programı GPT-4’ün ayrıntılarını yayınlamayı reddederek araştırma topluluğunu Nisan ayında şaşırtan Google’ın ana rakiplerinden biri olan OpenAI’ye bir yanıttır. Önde gelen yapay zeka akademisyenleri, OpenAI’nin şaşırtıcı seçiminin sektör genelinde bilgi ifşası üzerinde caydırıcı bir etkiye sahip olabileceği ve PaLM 2 belgesinin haklı olabileceklerinin ilk büyük işareti olduğu konusunda uyarıda bulundu.
(Ayrıca birde şu var bir blog yazısı PaLM 2’nin yeni öğelerini özetleyen, ancak teknik ayrıntılar içermeyen).
Google onlarca yıllık açık yayıncılığı tersine çeviriyor
PaLM 2, GPT-4 gibi, (istemli) istemlere yanıt olarak metin grupları üretebilen, soruları yanıtlama ve yazılım kodlama gibi bir dizi görevi gerçekleştirmesine izin veren üretken bir yapay zeka programıdır.
OpenAI gibi, Google da AI araştırmasında onlarca yıllık açık yayıncılığı tersine çeviriyor. Bu, ” başlıklı 2017 tarihli bir Google araştırma makalesidir.Tüm ihtiyacın olan dikkat“, The Transformer adlı devrim niteliğinde bir programı ayrıntılı olarak ortaya çıkardı. Bu program, doğal dil işleme programları geliştirmek için yapay zeka araştırma topluluğunun ve endüstrinin çoğu tarafından hızla benimsendi.
Bu türevler arasında, ChatGPT için dünya çapında coşkuyu ateşleyen program olan OpenAI tarafından sonbaharda açıklanan ChatGPT programı var.
Bir makine öğrenimi programının eğitildiği veri miktarı ile programın boyutu arasında ideal bir denge vardır.
Ashish Vaswani dahil orijinal makalenin yazarlarından hiçbiri PaLM 2’nin yazarları arasında yer almıyor.
Her nasılsa, PaLM 2’nin The Transformer’ın soyundan geldiğini tek bir paragrafta ortaya koyarak ve başka bir şey açıklamayı reddederek, şirketin araştırmacıları hem alana katkılarını hem de bu araştırma ilerlemelerini paylaşma geleneğine son verme niyetlerini açıkça gösteriyor.
Makalenin geri kalanı, kullanılan eğitim verilerine ve programın parlamasını sağlayan kıyaslama puanlarına odaklanmaktadır.
Bu makale, yapay zeka araştırma literatüründen yola çıkarak önemli bir içgörü sunar: Bir makine öğrenimi programının eğitildiği veri miktarı ile programın boyutu arasında ideal bir denge vardır.
Yazarlar, program boyutu ile eğitim verisi miktarı arasında doğru dengeyi bularak PaLM 2 programını bir diyete sokabildiler, böylece programın kendisi orijinal PaLM programından çok daha küçük, diye yazıyorlar. Yapay zeka eğiliminin son zamanlarda giderek daha büyük bir ölçekte ters yönde olduğu göz önüne alındığında, bu önemli görünüyor.
Yazarlar yazarken,
“PaLM 2 ailesindeki en büyük model olan PaLM 2-L, en büyük PaLM modelinden önemli ölçüde daha küçüktür, ancak eğitim için daha fazla hesaplama kullanır. Değerlendirme sonuçlarımız, PaLM 2 modellerinin PaLM modellerinden önemli ölçüde daha iyi performans gösterdiğini gösteriyor. doğal dil oluşturma, çeviri ve muhakeme dahil olmak üzere görevler. daha yüksek kaliteli model, çıkarım verimliliğini büyük ölçüde artırır, hizmet maliyetini düşürür ve ‘daha fazla sayıda uygulama ve kullanıcı için modelin aşağı akış uygulamasını’ etkinleştirir.
PaLM 2’nin yazarları, programın boyutu ile eğitim verisi miktarı arasında bir orta yol olduğunu iddia ediyor. Yazarların tek bir tabloda vurguladığı gibi, PaLM ile karşılaştırıldığında PaLM 2 programları kıyaslama testlerinde doğrulukta belirgin bir gelişme gösteriyor:

Google
Bu nedenle, yapay zeka programları ölçeğinde son iki yıldaki pratik araştırmaların gözlemlerine dayanmaktadırlar.
Örneğin, yaygın olarak alıntılanan çalışma Geçen yıl Jordan Hoffman ve Google’ın DeepMind’daki meslektaşları tarafından yapılan çalışma, şimdi Chinchilla’nın pratik kuralı olarak bilinen, eğitim verisi miktarını ve programın boyutunu dengelemek için formül olan şeyi icat etti.
PaLM 2 bilim adamları, Hoffman ve ekibininkinden biraz farklı rakamlar elde ettiler, ancak bu rakamlar makalenin vardığı sonuçları doğruluyor. Sonuçlarını Chinchilla’nın çalışmasıyla kafa kafaya tek bir ölçeklendirme çizelgesinde sunuyorlar:
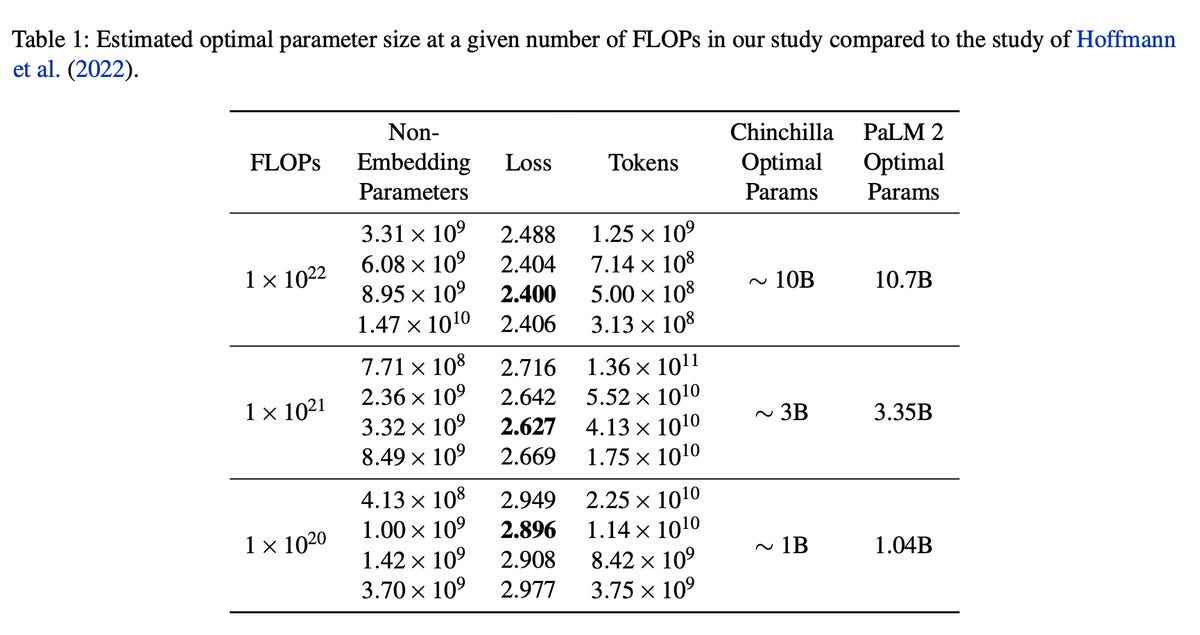
Google
Bu fikir, Kasım ayında egzersiz verilerini etiketlemek için araçlar açıklayan San Francisco merkezli üç yıllık bir yapay zeka girişimi olan Snorkel gibi genç şirketlerin çabalarıyla aynı çizgide. Snorkel, daha iyi veri iyileştirmenin gereken bazı hesaplamaları azaltabileceğini varsayar.
“Tatlı noktaya” odaklanma, orijinal PaLM modelinden biraz farklıdır. Bu model ile, Google işaret etti Google’ın TPU bilgisayar çiplerine atıfta bulunarak, programın eğitiminin ölçeği, “bugüne kadar eğitim için kullanılan en büyük TPU tabanlı sistem yapılandırması” olduğunu belirtti.
Bu kez böyle bir şey duyurulmadı. PaLM 2’nin yeni çalışmasında o kadar az şey ortaya çıkıyor ki, boyut uğruna boyuttan uzaklaşıp ölçek ve yeteneğin daha düşünceli bir şekilde ele alınmasına yönelik eğilimi doğruladığı söylenebilir.
Kaynak : “ZDNet.com”