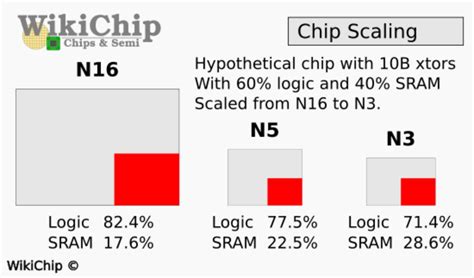

Yepyeni fabrikasyon düğümleri söz konusu olduğunda, performansı artırmalarını, güç tüketimini azaltmalarını ve transistör yoğunluğunu artırmalarını bekliyoruz. Ancak, mantık devreleri en son işlem teknolojileriyle iyi bir şekilde ölçeklenirken, SRAM hücreleri geride kalıyor ve görünüşe göre TSMC’nin 3nm sınıfı üretim düğümlerinde ölçeklenmeyi neredeyse durdurdu. Bu, yavaş SRAM hücreleri alan ölçeklendirmesi nedeniyle muhtemelen daha pahalı hale gelecek olan gelecekteki CPU’lar, GPU’lar ve SoC’ler için büyük bir sorundur.
TSMC, bu yılın başlarında N3 fabrikasyon teknolojilerini resmi olarak tanıttığında, yeni düğümlerin, N5 (5nm sınıfı) sürecine kıyasla mantık yoğunluğunda 1,6 kat ve 1,7 kat iyileştirme sağlayacağını söyledi. Ortaya çıkarmadığı şey, yeni teknolojilerin SRAM hücrelerinin N5’e kıyasla neredeyse ölçeklenmediğidir. WikiChipUluslararası Elektron Cihazları Toplantısında (IEDM) yayınlanan bir TSMC makalesinden bilgi alan
TSMC’nin N3’ü, N5’in 0,021 µm^²SRAM bit hücresine kıyasla yalnızca ~%5 daha küçük olan 0,0199µm^²’lik bir SRAM bit hücresi boyutuna sahiptir. 0,021 µm^² SRAM bit hücresi (kabaca 31,8 Mib/mm^²’ye çevrilir) ile birlikte gelen yenilenen N3E ile durum daha da kötüleşiyor, bu da N5’e kıyasla hiç ölçeklendirme olmadığı anlamına geliyor.
Bu arada Intel’in Intel 4’ü (başlangıçta 7nm EUV olarak adlandırılır), Intel 7 (eski adıyla 10nm Enhanced SuperFin) durumunda SRAM bitcell boyutunu 0,0312µm^²’den 0,024µm^²’ye düşürür, hala 27,8 Mib/mm gibi bir şeyden bahsediyoruz ^², TSMC’nin HD SRAM yoğunluğunun biraz gerisindedir.
Üstelik, WikiChip Forksheet transistörlü ‘2nm’nin ötesinde bir düğümde’ yaklaşık 60 Mib/mm^² SRAM yoğunlukları gösteren bir Imec sunumunu hatırlıyor. Bu tür bir işlem teknolojisine daha yıllar var ve çip tasarımcıları arada sırada Intel ve TSMC tarafından reklamı yapılan SRAM yoğunluklarına sahip işlemciler geliştirmek zorunda kalacaklar (yine de Intel 4 zaten Intel dışında kimse tarafından kullanılmayacak).
Modern CPU’lar, GPU’lar ve SoC’ler, bir sürü veriyi işlerken çeşitli önbellekler için bir sürü SRAM kullanır ve özellikle çeşitli yapay zeka (AI) ve makine öğrenimi (ML) iş yükleri için bellekten veri almak son derece verimsizdir. Ancak akıllı telefonlar için genel amaçlı işlemciler, grafik yongaları ve uygulama işlemcileri bile bugünlerde çok büyük önbellekler taşıyor: AMD’nin Ryzen 9 7950X’i toplamda 81MB önbellek taşırken Nvidia’nın AD102’si, Nvidia’nın kamuya açıkladığı çeşitli önbellekler için en az 123MB SRAM kullanıyor.
İleriye dönük olarak, önbellek ve SRAM ihtiyacı yalnızca artacaktır, ancak N3 (yalnızca birkaç ürün için kullanılmak üzere ayarlanmıştır) ve N3E ile SRAM tarafından işgal edilen kalıp alanını azaltmanın ve yeni ürünün daha yüksek maliyetlerini azaltmanın hiçbir yolu olmayacaktır. N5 ile karşılaştırıldığında düğüm. Temel olarak, bu, yüksek performanslı işlemcilerin kalıp boyutlarının ve dolayısıyla maliyetlerinin artacağı anlamına gelir. Bu arada, tıpkı mantık hücreleri gibi, SRAM hücreleri de kusurlara eğilimlidir. Yonga tasarımcıları, N3’ün FinFlex yenilikleriyle (performans, güç veya alan için optimize etmek üzere bir blokta farklı FinFET türlerini karıştırma ve eşleştirme) bir dereceye kadar daha büyük SRAM hücrelerini hafifletebilecekler, ancak bu noktada yalnızca ne tür olduğunu tahmin edebiliriz. Bunun getireceği meyveler.
TSMC, N5’e kıyasla SRAM bit hücresi boyutunu küçültmeyi vaat eden yoğunluğu optimize edilmiş N3S işlem teknolojisini getirmeyi planlıyor, ancak bu yaklaşık 2024’te gerçekleşecek ve bunun AMD, Apple tarafından tasarlanan yongalar için yeterli mantık performansı sağlayıp sağlayamayacağını merak ediyoruz. Nvidia ve Qualcomm.
Yavaşlayan SRAM alan ölçeklemesini maliyet açısından azaltmanın yollarından biri, çoklu yonga tasarımına geçmek ve daha büyük önbellekleri daha ucuz bir düğümde yapılan ayrı kalıplara ayırmaktır. Bu, AMD’nin 3D V-Cache ile yaptığı bir şeydir, ancak biraz farklı bir nedenle (şimdilik). Başka bir yol da, önbellekler için eDRAM veya FeRAM gibi alternatif bellek teknolojilerini kullanmaktır, ancak ikincisinin kendine has özellikleri vardır.
Her halükarda, FinFET tabanlı düğümlerle SRAM ölçeklendirmesinin 3nm ve ötesinde yavaşlaması, önümüzdeki yıllarda çip tasarımcıları için büyük bir zorluk gibi görünüyor.
genel-21