
Meta var piyasaya sürülmüş Llama serisi açık üretken yapay zeka modellerinin en son üyesi: Llama 3. Daha doğrusu şirket, yeni Llama 3 ailesinde iki modeli piyasaya sürdü, geri kalanı belirsiz bir gelecekte gelecek.
Meta, 8 milyar parametre içeren Llama 3 8B ve 70 milyar parametre içeren Llama 3 70B adlı yeni modelleri, önceki nesil Llama modelleri Llama 2 8B ve Llama 2 70B ile karşılaştırıldığında “büyük bir sıçrama” olarak tanımlıyor. performans açısından. (Parametreler esasen bir yapay zeka modelinin bir problem üzerindeki becerisini tanımlar; metin analiz etmek ve oluşturmak gibi; yüksek parametre sayılı modeller, genel olarak konuşursak, düşük parametre sayılı modellere göre daha yeteneklidir.) Aslında Meta şunu söylüyor: ilgili parametre sayıları, Llama 3 8B ve Llama 3 70B — özel olarak oluşturulmuş iki 24.000 GPU kümesi üzerinde eğitilmiştir – günümüzün en iyi performans gösteren üretken yapay zeka modelleri arasındadır.
Bu oldukça iddialı bir iddia. Peki Meta bunu nasıl destekliyor? Şirket, Llama 3 modellerinin MMLU (bilgiyi ölçmeye çalışan), ARC (beceri edinimini ölçmeye çalışan) ve DROP (bir modelin metin parçaları üzerinde mantığını test eden) gibi popüler AI kriterlerindeki puanlarına dikkat çekiyor. Daha önce de yazdığımız gibi, bu kriterlerin yararlılığı ve geçerliliği tartışmaya açıktır. Ancak iyi de olsa kötü de olsa, Meta gibi yapay zeka oyuncularının modellerini değerlendirdiği birkaç standart yoldan biri olmaya devam ediyorlar.
Llama 3 8B, her ikisi de 7 milyar parametre içeren Mistral’in Mistral 7B ve Google’ın Gemma 7B’si gibi diğer açık modellerden en az dokuz kıyaslamada en iyi sonucu verir: MMLU, ARC, DROP, GPQA (bir dizi biyoloji, fizik ve kimya) ilgili sorular), HumanEval (bir kod oluşturma testi), GSM-8K (matematik kelime problemleri), MATH (başka bir matematik kıyaslaması), AGIEval (bir problem çözme test seti) ve BIG-Bench Hard (sağduyulu bir akıl yürütme değerlendirmesi).
Şimdi, Mistral 7B ve Gemma 7B tam olarak son teknolojide değiller (Mistral 7B geçen Eylül ayında piyasaya sürüldü) ve Meta’nın belirttiği birkaç kıyaslamada Llama 3 8B her ikisinden de yalnızca birkaç yüzde puan daha yüksek puan alıyor. Ancak Meta aynı zamanda daha büyük parametre sayısına sahip Llama 3 modeli Llama 3 70B’nin, aralarında Google’ın Gemini serisinin en sonuncusu olan Gemini 1.5 Pro’nun da bulunduğu amiral gemisi üretken yapay zeka modelleriyle rekabet edebileceğini de iddia ediyor.
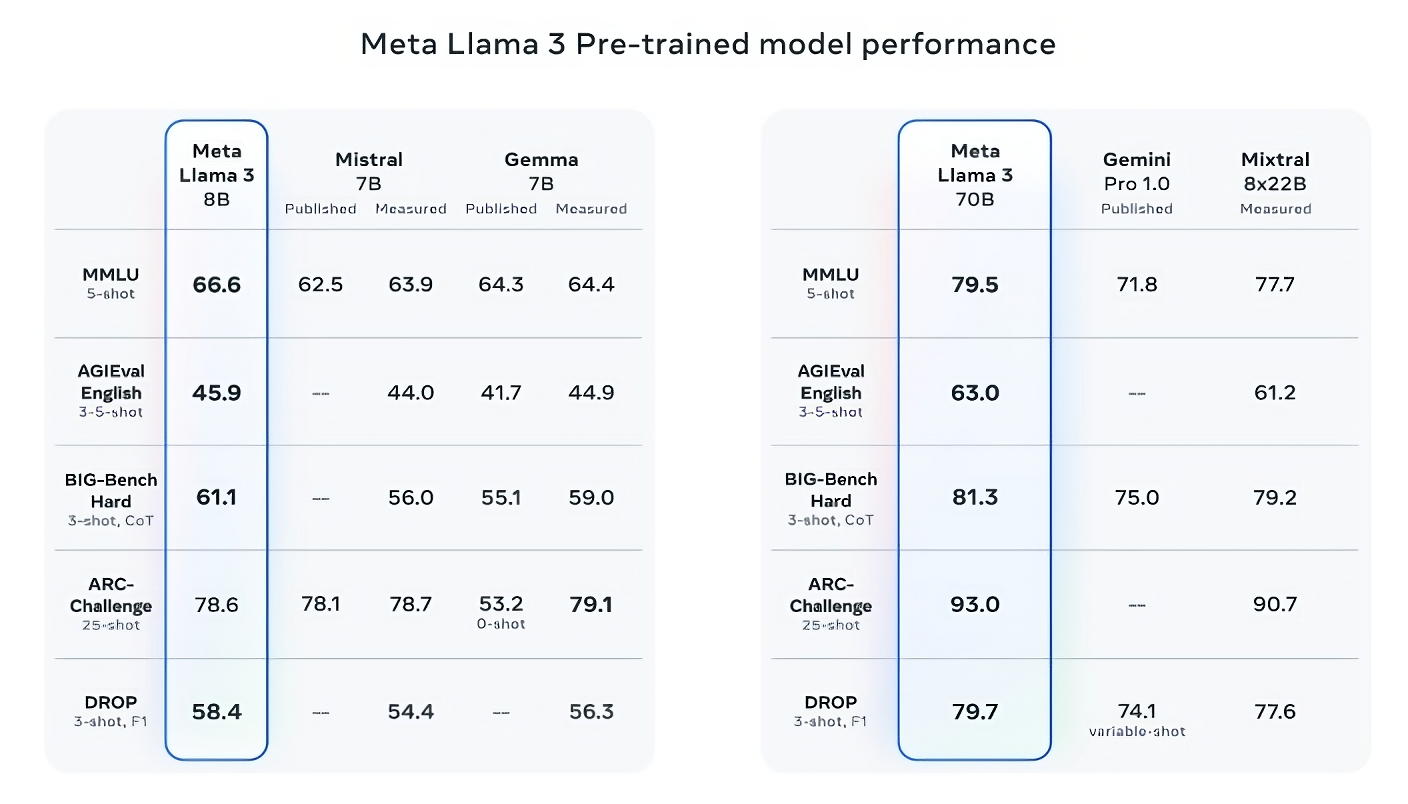
Resim Kredisi: Meta
Llama 3 70B, MMLU, HumanEval ve GSM-8K’de Gemini 1.5 Pro’yu yener ve Anthropic’in en performanslı modeli olan Claude 3 Opus’a rakip olmasa da Llama 3 70B, Claude 3 serisinin en zayıf ikinci modelinden daha iyi puan alır. Claude 3 Sonnet, beş kritere göre (MMLU, GPQA, HumanEval, GSM-8K ve MATH).
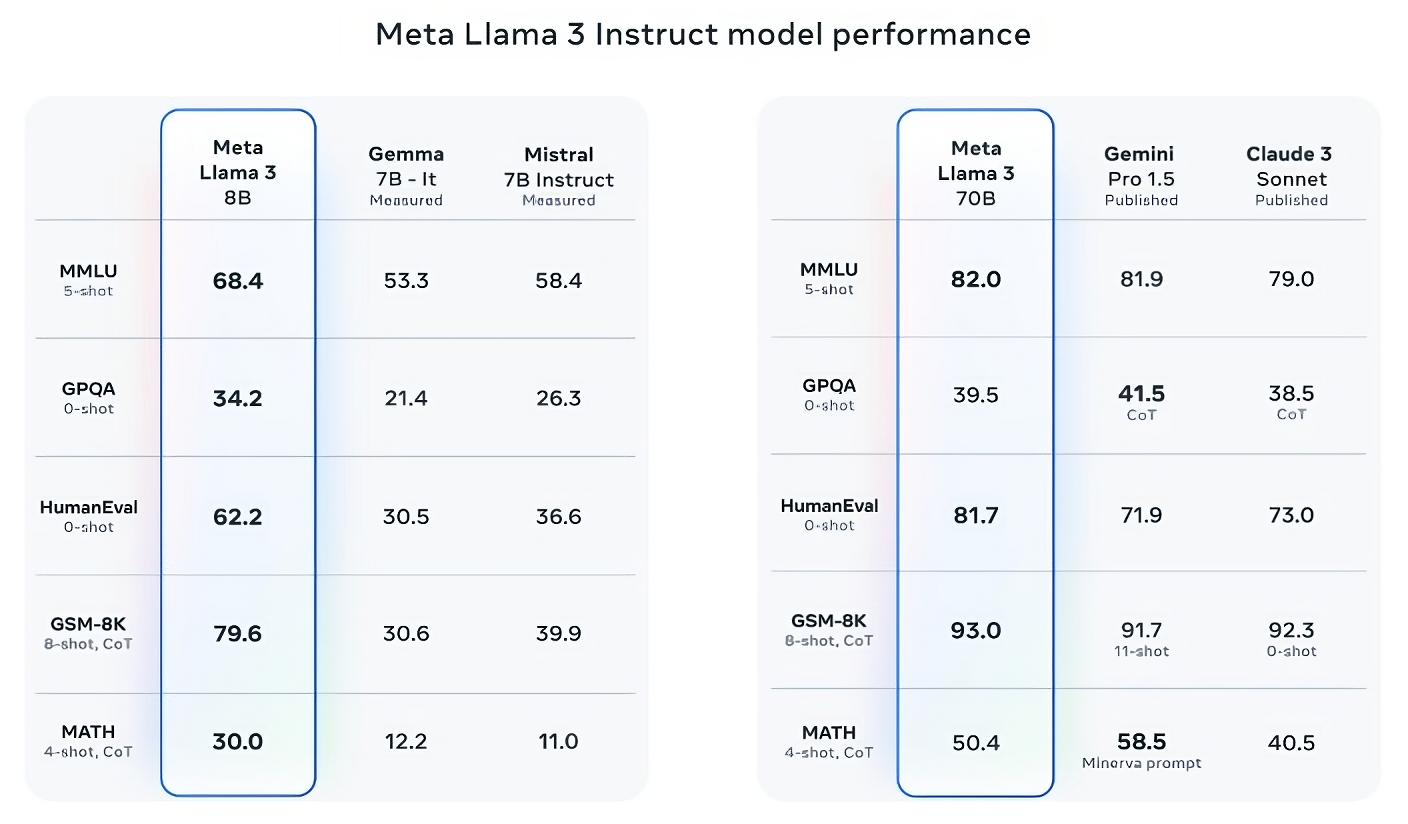
Resim Kredisi: Meta
Ne olursa olsun Meta, kodlama ve yaratıcı yazarlıktan akıl yürütmeye ve özetlemeye kadar çeşitli kullanım örneklerini kapsayan kendi test setini de geliştirdi ve – sürpriz! — Llama 3 70B, Mistral’ın Mistral Medium modeli, OpenAI’nin GPT-3.5’i ve Claude Sonnet’e karşı birinci oldu. Meta, nesnelliği korumak için modelleme ekiplerinin sete erişimini engellediğini söylüyor ancak açıkçası – testi Meta’nın kendisi tasarladığı göz önüne alındığında – sonuçlara biraz ihtiyatlı yaklaşmak gerekiyor.

Resim Kredisi: Meta
Daha niteliksel olarak Meta, yeni Lama modellerinin kullanıcılarının daha fazla “yönlendirilebilirlik”, soruları yanıtlamayı reddetme olasılığının daha düşük olması ve önemsiz sorular, tarih ve mühendislik, bilim ve genel kodlama gibi STEM alanlarıyla ilgili sorularda daha yüksek doğruluk beklemeleri gerektiğini söylüyor. tavsiyeler. Bu kısmen çok daha büyük bir veri kümesi sayesinde: 15 trilyon jetondan oluşan bir koleksiyon veya akıllara durgunluk veren ~750.000.000.000 kelime – Llama 2 eğitim setinin yedi katı büyüklüğünde. (Yapay zeka alanında “jetonlar”, “fantastik” kelimesindeki “fan”, “tas” ve “tic” heceleri gibi ham verilerin alt bölümlere ayrılmış bitlerini ifade eder.)
Bu veriler nereden geldi? İyi soru. Meta bunu söylemedi ve yalnızca “kamuya açık kaynaklardan” yararlandığını, Llama 2 eğitim veri setindekinden dört kat daha fazla kod içerdiğini ve bu setin %5’inin iyileştirilmesi gereken İngilizce olmayan verilere (yaklaşık 30 dilde) sahip olduğunu açıkladı. İngilizce dışındaki dillerde performans. Meta ayrıca Llama 3 modellerinin üzerinde eğitim alabileceği daha uzun belgeler oluşturmak için sentetik verileri (yani yapay zeka tarafından oluşturulan verileri) kullandığını söyledi. biraz tartışmalı bir yaklaşım Potansiyel performans dezavantajları nedeniyle.
Meta, TechCrunch ile paylaştığı bir blog yazısında şöyle yazıyor: “Bugün yayınladığımız modeller yalnızca İngilizce çıktılar için ince ayarlı olsa da, artan veri çeşitliliği, modellerin nüansları ve kalıpları daha iyi tanımasına ve çeşitli görevlerde güçlü performans göstermesine yardımcı oluyor.”
Birçok üretken yapay zeka tedarikçisi, eğitim verilerini rekabet avantajı olarak görüyor ve bu nedenle bu verileri ve onunla ilgili bilgileri gizli tutuyor. Ancak eğitim verileri ayrıntıları aynı zamanda fikri mülkiyetle ilgili davaların da potansiyel bir kaynağıdır; bu da pek çok şeyin ortaya çıkmasını engelleyen başka bir engeldir. Son raporlama Meta’nın, AI rakiplerine ayak uydurma arayışında, şirketin kendi avukatlarının uyarılarına rağmen bir noktada AI eğitimi için telif hakkıyla korunan e-kitaplar kullandığını ortaya çıkardı; Meta ve OpenAI, satıcıların telif hakkıyla korunan verileri eğitim amacıyla izinsiz kullandığı iddiasıyla aralarında komedyen Sarah Silverman’ın da bulunduğu yazarlar tarafından açılan ve devam eden bir davanın konusu.
Peki üretken yapay zeka modellerindeki diğer iki yaygın sorun olan toksisite ve önyargı hakkında ne düşünüyorsunuz (Lama 2 dahil)? Llama 3 bu alanlarda gelişiyor mu? Evet, Meta’yı iddia ediyor.
Meta, model eğitim verilerinin kalitesini artırmak için yeni veri filtreleme hatları geliştirdiğini ve Llama Guard ve CybersecEval adlı üretken yapay zeka güvenlik paketlerini güncelleyerek, istenmeyen metin nesillerinin kötüye kullanılmasını önlemeye çalıştığını söylüyor. Lama 3 modelleri ve diğerleri. Şirket ayrıca, güvenlik açıklarına neden olabilecek üretken yapay zeka modellerindeki kodları tespit etmek için tasarlanmış yeni bir araç olan Code Shield’i de piyasaya sürüyor.
Ancak filtreleme kusursuz değildir ve Llama Guard, CyberSecEval ve Code Shield gibi araçlar ancak bu kadar ileri gidebilir. (Bakınız: Lama 2’nin eğilimi sorulara yanıtlar uydurmak ve özel sağlık ve mali bilgileri sızdırmak.) Akademisyenlerin alternatif kıyaslama testleri de dahil olmak üzere Llama 3 modellerinin vahşi ortamda nasıl performans gösterdiğini bekleyip görmemiz gerekecek.
Meta, şu anda indirilebilen ve Meta’nın Meta AI asistanını Facebook, Instagram, WhatsApp, Messenger ve web üzerinde güçlendiren Llama 3 modellerinin yakında AWS de dahil olmak üzere çok çeşitli bulut platformlarında yönetilen biçimde barındırılacağını söylüyor. Databricks, Google Cloud, Hugging Face, Kaggle, IBM’in WatsonX’i, Microsoft Azure, Nvidia’nın NIM’i ve Snowflake. Gelecekte AMD, AWS, Dell, Intel, Nvidia ve Qualcomm’un donanım için optimize edilmiş modellerinin versiyonları da satışa sunulacak.
Llama 3 modelleri yaygın olarak bulunabilmektedir. Ancak bunları tanımlamak için “açık kaynak” yerine “açık” kullandığımızı fark edeceksiniz. Çünkü buna rağmen Meta’nın iddialarıLama ailesindeki modeller, insanların inandığı kadar koşulsuz değil. Evet, hem araştırma hem de ticari uygulamalar için kullanılabilirler. Ancak Meta yasaklıyor geliştiricilerin diğer üretken modelleri eğitmek için Llama modellerini kullanmasına izin verilmezken, aylık 700 milyondan fazla kullanıcısı olan uygulama geliştiricilerinin Meta’dan, şirketin kendi takdirine bağlı olarak vereceği veya vermeyeceği özel bir lisans talep etmesi gerekiyor.
Ufukta daha yetenekli Lama modelleri görünüyor.
Meta, şu anda Llama 3 modellerini 400 milyarın üzerinde parametre boyutunda eğittiğini söylüyor – “birden fazla dilde konuşma”, daha fazla veri alma ve metinlerin yanı sıra görüntüleri ve diğer yöntemleri anlama yeteneğine sahip modeller, bu da Llama 3 serisini beraberinde getirecek Hugging Face’s gibi açık yayınlara uygun olarak İdefikler2.

Resim Kredisi: Meta
“Yakın gelecekteki hedefimiz, Llama 3’ü çok dilli ve çok modlu hale getirmek, daha uzun bir bağlama sahip olmak ve çekirdek genelinde genel performansı iyileştirmeye devam etmektir. [large language model] akıl yürütme ve kodlama gibi yetenekler,” diye yazıyor Meta bir blog yazısında. “Daha gelecek çok şey var.”
Aslında.
genel-24